Difference Between Logistic and Linear Regression
Statistical modeling plays a central role in modern academic research. Across disciplines such as business, healthcare, psychology, education, and engineering, researchers rely on regression analysis to understand relationships between variables, test hypotheses, and generate predictive insights. Among the most commonly used regression techniques are linear regression and logistic regression. Although these two models belong to the broader family of regression methods, they are designed for fundamentally different types of research questions and data structures.
Many graduate students and doctoral researchers struggle to clearly understand the difference between logistic and linear regression, especially when preparing dissertations or conducting empirical research. Choosing the wrong model can lead to invalid findings, incorrect interpretations, and rejected manuscripts. This is why proper statistical guidance is essential during the research process.
At SPSS Dissertation Help, our professional statisticians frequently assist students with regression modeling, ensuring the correct statistical method is applied based on the nature of the dependent variable and research objectives. Researchers seeking guidance on regression modeling often consult services such as SPSS Dissertation Help, Dissertation Statistics Consultant, and Hire Statistician for Dissertation to ensure their statistical analyses meet academic standards.
This guide provides a comprehensive explanation of the differences between logistic regression and linear regression. The discussion will cover theoretical foundations, mathematical principles, assumptions, interpretation techniques, practical examples, and statistical software implementation. By the end of this guide, researchers will understand when to apply each model and how to interpret results correctly.
Understanding Regression Analysis in Research
Regression analysis refers to a family of statistical techniques used to estimate the relationship between a dependent variable and one or more independent variables. These models help researchers quantify how changes in predictor variables influence an outcome variable.
Regression models are widely used for several purposes:
• Predicting outcomes based on explanatory variables
• Testing research hypotheses
• Identifying significant predictors
• Quantifying relationships between variables
• Modeling complex datasets
The specific regression technique used depends largely on the type of dependent variable.
If the dependent variable is continuous, linear regression is typically appropriate. If the dependent variable represents categories or probabilities, logistic regression becomes the preferred model.
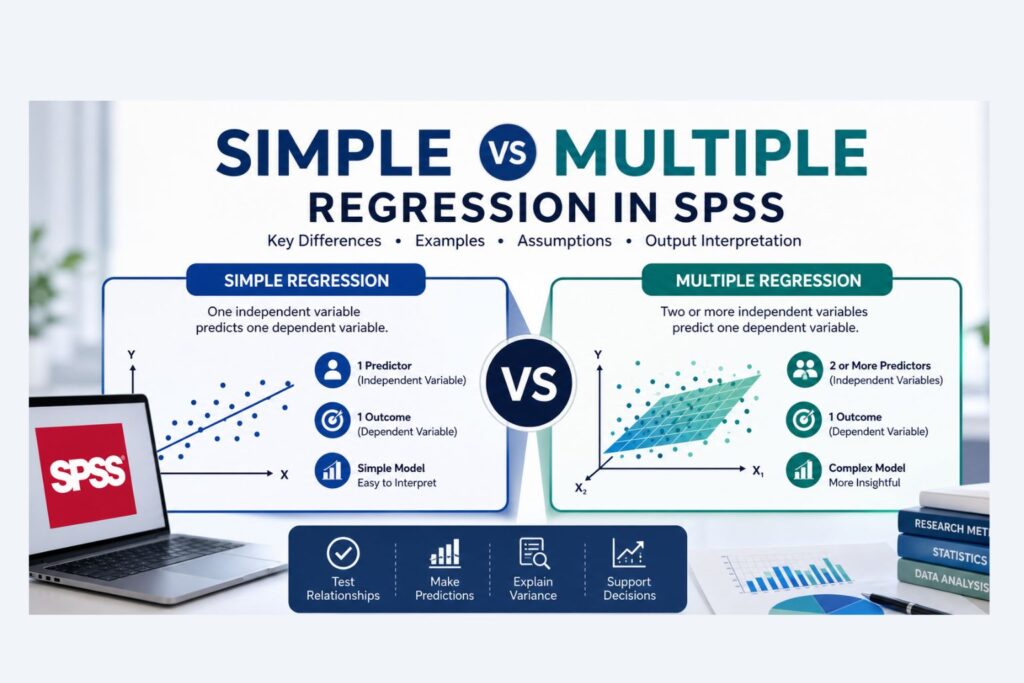
Types of Regression Models Used in Research
Several regression techniques are used in quantitative research, each suited to specific data structures.
Table: Common Regression Models and Their Applications
| Regression Type | Dependent Variable Type | Typical Application |
|---|---|---|
| Linear Regression | Continuous | Predicting income, sales, GPA |
| Logistic Regression | Binary | Disease diagnosis, purchase decision |
| Multinomial Logistic Regression | Categorical (multiple classes) | Brand choice modeling |
| Ordinal Logistic Regression | Ordered categories | Satisfaction scales |
| Poisson Regression | Count data | Number of events |
Among these techniques, linear regression and logistic regression are the most widely used in academic research.
Researchers frequently request assistance from SPSS Expert Online and Statistics Homework Help services when implementing regression models, especially when dealing with complex datasets or interpretation challenges.
What Is Linear Regression
Linear regression is a statistical technique used to model the relationship between a continuous dependent variable and one or more independent variables. The model assumes that the relationship between variables can be represented by a straight line.
The general equation of linear regression is:
Y = β₀ + β₁X₁ + β₂X₂ + … + ε
Where:
• Y represents the dependent variable
• β₀ represents the intercept
• β₁ represents regression coefficients
• X represents predictor variables
• ε represents the error term
Linear regression attempts to estimate the values of the coefficients that minimize the difference between predicted values and observed values.
Example of Linear Regression in Research
Suppose a researcher wants to examine whether study hours influence students’ exam scores.
In this scenario:
Dependent variable: Exam score (continuous)
Independent variable: Study hours
A linear regression model would estimate how much exam scores increase with each additional hour of study.
Table: Example Linear Regression Dataset
| Student | Study Hours | Exam Score |
|---|---|---|
| A | 3 | 65 |
| B | 5 | 72 |
| C | 7 | 80 |
| D | 9 | 88 |
| E | 10 | 91 |
Using linear regression, the researcher could estimate the expected increase in exam scores associated with each additional hour of study.
Researchers conducting such analyses frequently consult Dissertation Data Analysis Help to ensure proper model construction and interpretation.
Key Characteristics of Linear Regression
Linear regression possesses several defining characteristics that distinguish it from other regression models.
Continuous Dependent Variable
The dependent variable must be continuous and measured on an interval or ratio scale.
Examples include:
• Income
• Height
• Blood pressure
• Test scores
• Sales revenue
Linear Relationship
The model assumes that the relationship between predictors and the outcome variable is linear.
Normally Distributed Residuals
Residuals, or prediction errors, should follow a normal distribution.
Homoscedasticity
The variance of residuals should remain constant across levels of the predictor variables.
Independence of Observations
Each observation in the dataset should be independent of the others.
Violating these assumptions can lead to biased estimates and inaccurate statistical conclusions.
For this reason, researchers often seek guidance from SPSS Assignment Help when diagnosing regression assumptions.
What Is Logistic Regression
Logistic regression is used when the dependent variable is categorical rather than continuous. Most commonly, logistic regression is used for binary outcomes, where the dependent variable has two possible categories.
Examples include:
• Disease vs no disease
• Purchase vs no purchase
• Success vs failure
• Employed vs unemployed
Instead of predicting the exact value of an outcome, logistic regression predicts the probability that a particular outcome will occur.
The logistic regression equation is expressed using the logit transformation.
Logit(p) = ln(p / (1 − p)) = β₀ + β₁X₁ + β₂X₂
Where:
• p represents the probability of the event occurring
• ln represents the natural logarithm
• X represents independent variables
The model converts probabilities into log-odds, allowing relationships to be modeled linearly.
Example of Logistic Regression in Research
Imagine a healthcare researcher examining whether smoking and age predict the likelihood of developing heart disease.
Dependent variable:
Heart disease (Yes or No)
Independent variables:
Smoking status
Age
Table: Example Logistic Regression Dataset
| Participant | Age | Smoking | Heart Disease |
|---|---|---|---|
| 1 | 45 | Yes | Yes |
| 2 | 38 | No | No |
| 3 | 50 | Yes | Yes |
| 4 | 42 | No | No |
| 5 | 60 | Yes | Yes |
Logistic regression estimates the probability that an individual develops heart disease based on these predictors.
Researchers conducting health-related statistical analysis often rely on Nursing Dissertation Help and Statistical Analysis Help services for assistance with logistic regression models.
Why Logistic Regression Cannot Be Replaced by Linear Regression
One common mistake made by inexperienced researchers is attempting to apply linear regression to binary outcomes. This approach creates several statistical problems.
Predicted Values Outside the 0–1 Range
Linear regression can produce predicted values below zero or above one when modeling probabilities.
Non-Normal Error Distribution
Binary outcomes violate the normality assumption required by linear regression.
Heteroscedasticity
Variance in binary outcomes is not constant across predictor levels.
Logistic regression resolves these issues by modeling probabilities using the logistic function.
Table: Comparison of Outcome Prediction
| Model | Possible Predicted Values |
|---|---|
| Linear Regression | Negative or greater than 1 possible |
| Logistic Regression | Always between 0 and 1 |
Because of these limitations, logistic regression is the correct method for binary outcomes.
Researchers unsure about selecting the appropriate statistical technique often seek advice from Hire Statistician for Dissertation experts.
Mathematical Foundations of Linear and Logistic Regression
Although both models belong to the regression family, they differ substantially in their mathematical structure.
Linear Regression Mathematical Structure
Linear regression estimates coefficients using Ordinary Least Squares (OLS).
The goal of OLS is to minimize the sum of squared residuals.
The objective function is:
Minimize Σ(Yᵢ − Ŷᵢ)²
Where:
Yᵢ = observed values
Ŷᵢ = predicted values
Logistic Regression Mathematical Structure
Logistic regression does not rely on OLS estimation. Instead, it uses Maximum Likelihood Estimation (MLE).
MLE identifies the parameter values that maximize the probability of observing the sample data.
Table: Estimation Methods Comparison
| Model | Estimation Method |
|---|---|
| Linear Regression | Ordinary Least Squares |
| Logistic Regression | Maximum Likelihood Estimation |
Understanding these estimation techniques is essential when interpreting regression outputs.
Graduate students frequently consult Dissertation Results Help services to ensure their regression tables are correctly interpreted.
Regression Modeling in SPSS
Statistical software plays a critical role in regression analysis. Among academic researchers, SPSS remains one of the most widely used tools.
SPSS allows researchers to easily run both linear and logistic regression models using built-in procedures.
Typical steps include:
• Importing the dataset
• Defining dependent and independent variables
• Selecting regression type
• Checking statistical assumptions
• Interpreting coefficients
Many students rely on SPSS Data Analysis Help services when running regression models in SPSS for dissertations or thesis projects.
Proper interpretation of regression output tables is crucial for academic publication and dissertation approval.
Core Differences Between Logistic Regression and Linear Regression
Although both logistic regression and linear regression are widely used in statistical modeling, they serve different analytical purposes. Understanding the core differences between these two models is essential for researchers conducting quantitative studies in fields such as healthcare, business analytics, economics, education, and psychology.
The primary distinction between the two models lies in the type of dependent variable being analyzed. Linear regression is designed for continuous outcomes, whereas logistic regression is used when the outcome variable represents categorical events.
Table: Key Differences Between Logistic and Linear Regression
| Feature | Linear Regression | Logistic Regression |
|---|---|---|
| Dependent variable type | Continuous | Binary or categorical |
| Model output | Predicted value | Probability of event |
| Equation type | Linear equation | Logistic (S-shaped) function |
| Estimation method | Ordinary Least Squares | Maximum Likelihood Estimation |
| Interpretation | Change in dependent variable | Odds ratios or probability changes |
| Prediction range | Negative to positive infinity | Between 0 and 1 |
Researchers often encounter confusion when selecting the appropriate regression technique for their dissertation research. In such cases, professional consultation through SPSS Dissertation Help or Dissertation Statistics Consultant services can ensure correct model selection and interpretation.
Nature of the Dependent Variable
The type of dependent variable determines which regression model should be applied.
Continuous Outcomes in Linear Regression
Linear regression is used when the outcome variable represents measurable numerical values that can vary continuously.
Examples include:
• Salary levels
• Exam scores
• Blood pressure measurements
• Annual revenue
• Customer satisfaction scores
These outcomes can take a wide range of numeric values, making them appropriate for linear modeling.
Table: Examples of Linear Regression Applications
| Research Topic | Dependent Variable | Independent Variable |
|---|---|---|
| Education | Exam score | Study hours |
| Marketing | Sales revenue | Advertising budget |
| Healthcare | Blood pressure | Age |
| Finance | Stock returns | Market index |
Researchers performing such analyses frequently seek assistance from <b>SPSS Data Analysis Help</b> services to ensure that statistical assumptions are properly tested before model estimation.
Binary Outcomes in Logistic Regression
Logistic regression is applied when the outcome variable has two categories representing the occurrence or non-occurrence of an event.
Examples include:
• Loan approval vs rejection
• Customer purchase vs non-purchase
• Disease present vs absent
• Employee turnover vs retention
In these cases, the model estimates the probability that an observation belongs to one of the categories.
Table: Examples of Logistic Regression Applications
| Research Topic | Outcome Variable | Predictor Variable |
|---|---|---|
| Healthcare | Disease diagnosis | Lifestyle factors |
| Marketing | Product purchase | Advertising exposure |
| Finance | Loan default | Credit score |
| Education | Course completion | Study habits |
Researchers often seek support from Statistical Analysis Help and Statistics Homework Help services when implementing logistic regression models due to their more complex interpretation.
Differences in Model Output
Another important difference between linear regression and logistic regression lies in the nature of the model output.
Linear Regression Output
Linear regression directly predicts the value of the dependent variable.
For example:
A regression coefficient of 2.5 may indicate that each additional hour of study increases exam scores by 2.5 points.
The predicted value can be any real number depending on the data.
Logistic Regression Output
Logistic regression predicts the probability that an event occurs.
Instead of producing a numeric outcome, the model produces values between 0 and 1, representing probabilities.
Example interpretation:
A predicted probability of 0.75 means there is a 75% likelihood that the event will occur.
Table: Interpretation Differences
| Model | Example Interpretation |
|---|---|
| Linear Regression | Each extra hour of study increases exam score by 2.5 points |
| Logistic Regression | Probability of passing exam increases by 10% |
Correct interpretation of regression coefficients is essential for dissertation research. Students frequently request help from Hire Statistician for Dissertation experts to ensure regression results are presented correctly in Chapter 4 of their dissertations.
Shape of the Relationship
The relationship between independent variables and the dependent variable also differs significantly between the two models.
Linear Relationship in Linear Regression
Linear regression assumes a straight-line relationship between predictors and the outcome variable.
The relationship can be represented graphically as a straight line.
For example:
Exam Score = 50 + 3 × Study Hours
This means each additional hour increases the predicted score by 3 points.
S-Shaped Relationship in Logistic Regression
Logistic regression follows an S-shaped curve, known as the logistic function.
At low predictor values, the probability of the event occurring remains low. As predictor values increase, the probability rises rapidly before eventually leveling off.
Table: Functional Form Comparison
| Model | Relationship Type |
|---|---|
| Linear Regression | Straight-line relationship |
| Logistic Regression | Logistic curve (S-shape) |
Because probabilities cannot exceed 1 or fall below 0, logistic regression ensures predictions remain within valid bounds.
Researchers conducting advanced modeling frequently consult SPSS Expert Online services to visualize these relationships and confirm appropriate model selection.
Interpretation of Regression Coefficients
Regression coefficients represent the influence of predictor variables on the outcome variable. However, interpretation differs substantially between the two models.
Coefficients in Linear Regression
In linear regression, coefficients represent the direct change in the dependent variable for a one-unit increase in the predictor.
Example:
Coefficient for study hours = 4
Interpretation:
Each additional hour of study increases exam scores by 4 points.
This interpretation is straightforward because the model operates in the same scale as the dependent variable.
Coefficients in Logistic Regression
Logistic regression coefficients represent the change in log odds of the outcome.
Since log-odds are difficult to interpret directly, coefficients are usually transformed into odds ratios.
Odds Ratio Formula
Odds Ratio = e^β
Example:
Coefficient for smoking = 0.8
Odds ratio = e^0.8 = 2.22
Interpretation:
Smokers are 2.22 times more likely to develop the disease compared to non-smokers.
Table: Interpretation of Coefficients
| Model | Coefficient Meaning |
|---|---|
| Linear Regression | Change in dependent variable |
| Logistic Regression | Change in log odds of outcome |
Understanding odds ratios is critical for fields such as healthcare, epidemiology, and marketing research. Many researchers consult Nursing Dissertation Help specialists when interpreting logistic regression models in health research.
Assumptions of Linear Regression
Before running a linear regression model, several statistical assumptions must be satisfied.
Linearity
The relationship between predictors and outcome must be linear.
Normality of Residuals
Residuals should follow a normal distribution.
Homoscedasticity
Residuals must have constant variance across predictor levels.
Independence
Observations should not influence each other.
Absence of Multicollinearity
Independent variables should not be strongly correlated with one another.
Table: Linear Regression Assumptions
| Assumption | Description |
|---|---|
| Linearity | Predictors have linear relationship with outcome |
| Normality | Residuals follow normal distribution |
| Homoscedasticity | Constant variance of residuals |
| Independence | Observations are independent |
| Multicollinearity | Predictors not strongly correlated |
Researchers frequently request assistance from Dissertation Data Analysis Help services when testing these assumptions in SPSS.
Assumptions of Logistic Regression
Logistic regression has fewer strict assumptions than linear regression but still requires several conditions to be satisfied.
Binary Dependent Variable
The outcome variable must represent two categories.
Independent Observations
Observations must be independent.
Linearity of Logit
Predictor variables should have a linear relationship with the logit of the outcome.
No Multicollinearity
Predictor variables should not be highly correlated.
Table: Logistic Regression Assumptions
| Assumption | Explanation |
|---|---|
| Binary outcome | Dependent variable has two categories |
| Independence | Observations independent |
| Logit linearity | Predictors linear in log odds |
| No multicollinearity | Predictors not strongly correlated |
Graduate students often rely on SPSS Assignment Help when testing these assumptions for logistic regression models.
When Should Researchers Use Linear Regression
Linear regression is appropriate when:
• The dependent variable is continuous
• The goal is prediction of numeric values
• The relationship between variables is linear
Common research areas include:
• Finance
• Economics
• Business analytics
• Education performance research
When Should Researchers Use Logistic Regression
Logistic regression should be used when:
• The outcome variable is binary
• The objective is probability prediction
• The research question involves classification
Typical fields include:
• Healthcare research
• Customer behavior analysis
• Risk assessment
• Marketing analytics
Researchers unsure about selecting the appropriate model often consult Dissertation Results Help to ensure methodological accuracy.
Importance of Choosing the Correct Model
Selecting the wrong regression model can produce misleading results. Using linear regression for categorical outcomes can generate invalid probability predictions, while logistic regression applied to continuous outcomes can distort statistical relationships.
Accurate model selection ensures that research findings remain valid, reliable, and suitable for publication in peer-reviewed journals.
For this reason, many graduate students and doctoral researchers seek expert support through SPSS Dissertation Help when performing regression analysis for dissertations or theses.
Model Evaluation and Diagnostic Testing in Regression Analysis
Running a regression model is only the beginning of the statistical analysis process. After estimating the model, researchers must evaluate its performance and determine whether the model adequately fits the data. Model diagnostics help researchers determine the accuracy, reliability, and predictive strength of regression models.
The evaluation procedures differ between linear regression and logistic regression because the models estimate different types of outcomes.
Researchers working on dissertation-level statistical analysis often rely on SPSS Dissertation Help, Dissertation Data Analysis Help, and Dissertation Statistics Consultant services to perform regression diagnostics correctly and interpret the output tables in SPSS.
Model Evaluation in Linear Regression
Linear regression models are evaluated using several goodness-of-fit statistics that measure how well the model explains variation in the dependent variable.
R-Squared (Coefficient of Determination)
R-squared is one of the most commonly reported statistics in linear regression analysis. It represents the proportion of variance in the dependent variable that is explained by the independent variables.
The value of R-squared ranges from 0 to 1.
Example interpretation:
An R-squared value of 0.65 means that 65 percent of the variation in the dependent variable is explained by the predictors included in the model.
Table: Interpretation of R-Squared Values
| R-Squared Value | Interpretation |
|---|---|
| 0.10 | Weak explanatory power |
| 0.30 | Moderate explanatory power |
| 0.50 | Strong explanatory power |
| 0.70 or higher | Very strong explanatory power |
However, R-squared increases whenever new predictors are added to the model, even if those predictors are not meaningful.
Adjusted R-Squared
Adjusted R-squared corrects for the number of predictors included in the model. This statistic is particularly important in multiple regression models.
Table: R-Squared vs Adjusted R-Squared
| Statistic | Purpose |
|---|---|
| R-Squared | Measures variance explained by the model |
| Adjusted R-Squared | Adjusts for number of predictors |
Researchers preparing dissertation results frequently consult Dissertation Results Help services to ensure proper reporting of these statistics in their methodology and results chapters.
F-Test for Overall Model Significance
The F-test evaluates whether the regression model significantly predicts the dependent variable.
The null hypothesis states that all regression coefficients are equal to zero.
If the F-test is statistically significant (p < 0.05), it indicates that the model explains a significant portion of the variation in the outcome variable.
Table: Example Linear Regression Model Summary
| Statistic | Value |
|---|---|
| R-Squared | 0.61 |
| Adjusted R-Squared | 0.59 |
| F-Statistic | 18.45 |
| Significance | 0.001 |
In this example, the model explains 61 percent of the variance in the dependent variable and is statistically significant.
Researchers often request SPSS Data Analysis Help to correctly interpret these regression outputs.
Model Evaluation in Logistic Regression
Unlike linear regression, logistic regression does not use traditional R-squared values because the dependent variable is categorical rather than continuous.
Instead, logistic regression models rely on alternative evaluation metrics.
Pseudo R-Squared Measures
Pseudo R-squared statistics provide approximate measures of model fit.
Common pseudo R-squared statistics include:
• Cox and Snell R-Squared
• Nagelkerke R-Squared
• McFadden R-Squared
Table: Common Logistic Regression Fit Statistics
| Statistic | Purpose |
|---|---|
| Cox and Snell R² | Approximate model fit |
| Nagelkerke R² | Adjusted version of Cox and Snell |
| McFadden R² | Used in econometric models |
Example interpretation:
A Nagelkerke R-squared value of 0.48 suggests that the model explains approximately 48 percent of the variance in the outcome variable.
Researchers working on applied statistical modeling frequently consult Statistical Analysis Help when interpreting pseudo R-squared values.
Likelihood Ratio Test
The likelihood ratio test evaluates whether the logistic regression model significantly improves prediction compared to a model without predictors.
Table: Example Logistic Regression Model Fit
| Statistic | Value |
|---|---|
| -2 Log Likelihood | 152.44 |
| Chi-Square | 26.91 |
| Significance | 0.000 |
A significant chi-square value indicates that the model improves prediction of the outcome variable.
Graduate students often seek assistance from SPSS Assignment Help services when interpreting likelihood ratio tests in SPSS output.
Classification Accuracy in Logistic Regression
One of the unique features of logistic regression is its ability to classify observations into categories.
Classification accuracy measures how well the model correctly predicts outcomes.
Table: Example Classification Table
| Actual Outcome | Predicted Yes | Predicted No |
|---|---|---|
| Yes | 45 | 10 |
| No | 8 | 37 |
From this table, researchers calculate performance metrics.
Table: Logistic Regression Classification Metrics
| Metric | Meaning |
|---|---|
| Accuracy | Percentage of correct predictions |
| Sensitivity | Ability to correctly predict positive outcomes |
| Specificity | Ability to correctly predict negative outcomes |
These measures are widely used in healthcare research and marketing analytics.
Researchers conducting predictive modeling often request help from SPSS Expert Online to interpret classification tables and diagnostic metrics.
Residual Analysis in Linear Regression
Residuals represent the difference between observed and predicted values.
Analyzing residuals helps researchers identify potential model problems.
Key residual diagnostics include:
• Residual plots
• Normal probability plots
• Standardized residual analysis
Table: Common Residual Diagnostics
| Diagnostic | Purpose |
|---|---|
| Residual plot | Detect non-linearity |
| Normal probability plot | Test residual normality |
| Standardized residuals | Identify outliers |
Outliers with standardized residuals greater than ±3 may indicate problematic observations.
Researchers conducting detailed diagnostic analysis often rely on Hire Statistician for Dissertation services to ensure regression assumptions are satisfied.
Multicollinearity Testing in Regression
Multicollinearity occurs when independent variables are highly correlated with each other. This can distort regression coefficients and make interpretation difficult.
Multicollinearity is commonly evaluated using Variance Inflation Factor (VIF) and Tolerance statistics.
Table: Multicollinearity Thresholds
| Statistic | Acceptable Range |
|---|---|
| VIF | Less than 10 |
| Tolerance | Greater than 0.10 |
Example interpretation:
If a variable has a VIF value of 2.5, it indicates acceptable levels of multicollinearity.
Researchers frequently consult Statistics Homework Help when diagnosing multicollinearity in regression models.
Odds Ratios in Logistic Regression
One of the most important aspects of logistic regression interpretation is understanding odds ratios.
Odds ratios describe how the odds of an event change when a predictor variable increases by one unit.
Table: Example Logistic Regression Coefficients
| Predictor | Coefficient | Odds Ratio |
|---|---|---|
| Age | 0.45 | 1.57 |
| Smoking | 1.12 | 3.06 |
| Exercise | -0.52 | 0.59 |
Interpretation example:
• Smokers are 3.06 times more likely to develop the disease compared to non-smokers.
• Increased exercise reduces the probability of disease.
Researchers conducting health-related statistical analysis frequently rely on Nursing Dissertation Help when interpreting logistic regression odds ratios.
Practical Example Comparing Both Models
To illustrate the difference between logistic regression and linear regression, consider the following research scenarios.
Scenario 1: Predicting Salary
A researcher wants to examine whether education level and years of experience influence annual salary.
Dependent variable: Salary (continuous)
Appropriate model: Linear regression
Scenario 2: Predicting Job Placement
A researcher investigates whether GPA and internship experience influence whether a student obtains employment.
Dependent variable: Employment status (employed vs unemployed)
Appropriate model: Logistic regression
Table: Model Selection Example
| Research Question | Dependent Variable | Recommended Model |
|---|---|---|
| What predicts salary level | Continuous salary | Linear regression |
| What predicts job placement | Employed vs unemployed | Logistic regression |
Researchers working on dissertation research frequently consult Dissertation Data Analysis Help to determine which regression model should be applied.
Regression Implementation in SPSS
SPSS provides user-friendly procedures for running both regression models.
Running Linear Regression in SPSS
Steps include:
• Open dataset in SPSS
• Select Analyze
• Choose Regression
• Select Linear
Researchers then specify the dependent variable and predictor variables before running the model.
Running Logistic Regression in SPSS
Steps include:
• Select Analyze
• Choose Regression
• Select Binary Logistic
The dependent variable must be coded as binary.
Researchers frequently rely on SPSS Dissertation Help when performing regression analysis using SPSS for thesis or dissertation research.
Real Research Applications of Linear and Logistic Regression
Understanding theoretical differences between regression models is important, but researchers benefit even more from examining real-world research applications. Both linear regression and logistic regression are widely used across academic disciplines to answer different types of research questions.
Linear regression is most often used in research scenarios where the goal is to predict numerical outcomes. Logistic regression is used when the goal is to determine whether a particular event occurs.
Example Application in Business Research
In business analytics research, a study might investigate whether marketing investment predicts company revenue growth.
Dependent variable: Revenue growth (continuous)
Independent variables may include:
• Advertising budget
• Social media engagement
• Customer retention rate
Because revenue growth is a numerical variable, linear regression would be the appropriate modeling technique.
Table: Linear Regression Business Example
| Variable | Type | Role |
|---|---|---|
| Revenue Growth | Continuous | Dependent variable |
| Advertising Budget | Continuous | Independent variable |
| Social Media Engagement | Continuous | Independent variable |
| Customer Retention Rate | Continuous | Independent variable |
Researchers conducting such analyses frequently seek assistance from SPSS Dissertation Help to ensure regression results are interpreted correctly in academic dissertations.
Example Application in Healthcare Research
In healthcare studies, researchers often investigate whether certain risk factors influence disease occurrence.
Dependent variable: Presence of disease (Yes or No)
Independent variables may include:
• Age
• Smoking status
• Body mass index
• Physical activity level
Because the outcome variable is binary, logistic regression would be the appropriate statistical technique.
Table: Logistic Regression Healthcare Example
| Variable | Type | Role |
|---|---|---|
| Disease Presence | Binary | Dependent variable |
| Age | Continuous | Predictor |
| Smoking Status | Binary | Predictor |
| Body Mass Index | Continuous | Predictor |
Researchers conducting medical or nursing studies frequently rely on Nursing Dissertation Help and Statistical Analysis Help when performing logistic regression modeling.
Common Mistakes Researchers Make When Using Regression Models
Despite the popularity of regression analysis, many researchers make methodological mistakes that weaken the validity of their results. Understanding these common errors can help ensure stronger research outcomes.
Using Linear Regression for Binary Outcomes
One of the most common mistakes is using linear regression to analyze binary outcomes such as yes/no variables.
Because linear regression predicts values on an unrestricted scale, predicted probabilities can fall below zero or above one. This violates the theoretical assumptions of probability modeling.
Logistic regression corrects this issue by using the logistic transformation.
Ignoring Model Assumptions
Another common error is failing to test regression assumptions before interpreting results.
Important assumptions include:
• Linearity
• Independence of observations
• Absence of multicollinearity
• Normal distribution of residuals
Researchers frequently consult Dissertation Data Analysis Help services to ensure regression assumptions are properly tested before presenting results.
Misinterpreting Logistic Regression Coefficients
Logistic regression coefficients represent changes in log odds rather than direct changes in the dependent variable. Many researchers mistakenly interpret these coefficients as linear changes.
Instead, coefficients should be transformed into odds ratios for meaningful interpretation.
Overfitting the Regression Model
Overfitting occurs when researchers include too many predictor variables relative to the sample size. This can reduce the generalizability of the model and inflate statistical significance.
A commonly used guideline suggests that logistic regression models should have at least 10 observations per predictor variable.
Researchers conducting complex regression modeling frequently rely on Hire Statistician for Dissertation services to ensure their models remain statistically valid.
Best Practices for Reporting Regression Results
Academic journals and dissertation committees expect regression results to be reported using clear statistical standards. Researchers must present regression findings using structured tables and proper statistical interpretation.
Reporting Linear Regression Results
A typical regression results table should include:
• Regression coefficients
• Standard errors
• t-statistics
• p-values
• R-squared values
Table: Example Linear Regression Results
| Predictor | Coefficient | Standard Error | t-value | p-value |
|---|---|---|---|---|
| Intercept | 12.54 | 3.21 | 3.91 | 0.001 |
| Study Hours | 2.87 | 0.54 | 5.31 | 0.000 |
| Attendance | 1.12 | 0.48 | 2.33 | 0.022 |
Interpretation example:
Each additional hour of study increases exam scores by 2.87 points, holding other variables constant.
Researchers often seek Dissertation Results Help to ensure their regression tables are written correctly for dissertation chapters.
Reporting Logistic Regression Results
Logistic regression tables typically include:
• Coefficients
• Standard errors
• Wald statistics
• Odds ratios
• Significance values
Table: Example Logistic Regression Output
| Predictor | Coefficient | Odds Ratio | Wald Statistic | p-value |
|---|---|---|---|---|
| Age | 0.38 | 1.46 | 6.12 | 0.013 |
| Smoking | 1.21 | 3.35 | 9.41 | 0.002 |
| Exercise | -0.64 | 0.53 | 4.25 | 0.039 |
Interpretation example:
Smoking increases the odds of developing the disease by 3.35 times, while higher levels of exercise reduce the risk.
Researchers frequently rely on SPSS Expert Online services when preparing these tables for publication or thesis submissions.
Choosing the Correct Regression Model in Research
Selecting the correct statistical model depends primarily on the nature of the dependent variable and the research objective.
Table: Model Selection Guide
| Research Objective | Dependent Variable | Recommended Model |
|---|---|---|
| Predict numeric outcomes | Continuous | Linear Regression |
| Predict event probability | Binary | Logistic Regression |
| Predict multiple categories | Categorical | Multinomial Logistic Regression |
| Predict ordered categories | Ordinal | Ordinal Logistic Regression |
Graduate students working on dissertations frequently consult SPSS Assignment Help when determining which regression model should be applied.
Accurate model selection ensures that research findings remain statistically valid and academically credible.
Importance of Professional Statistical Support
Regression analysis may appear straightforward in statistical software, but the underlying methodological decisions require advanced statistical expertise. Researchers must carefully consider model selection, variable coding, diagnostic testing, and result interpretation.
For this reason, many graduate students and doctoral researchers rely on professional statistical consulting services such as:
• SPSS Dissertation Help
• Dissertation Statistics Consultant
• Statistics Homework Help
• SPSS Data Analysis Help
These services help ensure that regression analysis meets academic standards and supports reliable research conclusions.
Proper regression modeling is essential for producing credible research that can withstand peer review and academic evaluation.
Frequently Asked Questions
What is the main difference between logistic and linear regression
Linear regression predicts continuous numerical outcomes, while logistic regression predicts the probability of categorical events such as yes/no outcomes.
When should logistic regression be used instead of linear regression
Logistic regression should be used when the dependent variable represents categories, especially binary outcomes such as success or failure, disease presence, or purchase decisions.
Can logistic regression handle multiple predictor variables
Yes. Logistic regression can include multiple independent variables, allowing researchers to evaluate how several predictors influence the probability of an outcome.
Why can’t linear regression be used for classification problems
Linear regression can generate predicted values outside the range of 0 and 1, making it unsuitable for modeling probabilities. Logistic regression solves this issue by using a logistic function.
What statistical software is commonly used for regression analysis
Researchers commonly use SPSS, R, Stata, SAS, and Python to run regression models. Many students prefer SPSS because of its user-friendly interface.
Students who need help running regression models often consult SPSS Dissertation Help experts for guidance.
How do researchers interpret odds ratios in logistic regression
An odds ratio greater than one indicates increased likelihood of the outcome occurring, while an odds ratio less than one indicates a decrease in the likelihood of the event.
Request Quote for Regression Analysis Support
If you need professional assistance with regression analysis for your thesis or dissertation, our expert statisticians are ready to help.
Our services include:
• SPSS data analysis
• Logistic regression modeling
• Linear regression analysis
• Dissertation statistical consulting
• Data interpretation and reporting
Our team has extensive experience supporting master’s and doctoral researchers across multiple academic disciplines.
To receive expert support for your research, request a consultation through:
Our statisticians will review your dataset, research objectives, and methodology to provide accurate statistical guidance tailored to your study.
Request Quote: Get expert help with logistic and linear regression at SPSS Dissertation Help . Request your personalized quote today.